
We hereby offer to your attention a detailed guide to scraping web pages with python, using Selenium in the Python programming language.
Web scraping, occasionally referred to as web harvesting or web data extraction, is used for gathering specific data from websites, usually with the help of automated software.
This technique was designed with a view to simplify research by structuring data from multiple sources into a single asset that can later be analyzed and exploited. It can be achieved by leveraging the patterns in the page’s underlying code.
A great number of professional tools and skills, that simplify and boost the task’s efficiency, can be applied by users. For instance, Selenium, which is a widely used open-source portable framework, performs browser automation and is compatible with numerous programming languages.
While it is mostly used for automatically testing web applications or controlling web browsers, it also comes in handy for extracting data from websites.
Brief summary of the article:
- Necessary tools
- Preparation
- Key steps
- Results
- Optional features for advanced web scraping
- Concluding statements
Main goal
In this guide to web scraping, you’ll practice using Selenium on a webpage, demonstrated on the example of Zappos page with boots. You will have to search for a term, using the search box and scrape the headings of obtained results.
It should be noted that Zappos resorts to JavaScript in order to render content dynamically, that’s why it is perfect for case study in advanced websites scraping tutorials.
Necessary tools
- Python development environment
- Selenium
- Any web browser
Got it covered already? Let’s engage…
Necessary tools
In order to launch this scraping procedure, let’s start with installing Python bindings for Selenium and a relevant WebDriver for the browser we want to automate tasks on.
You should use a package installer for Python (otherwise called ‘pip’) to integrate Selenium with our development environment:
pip install seleniumKeep in mind that to work properly, Selenium needs the driver to emulate the regular behaviour of a living user with precision. Therefore, you better make sure you install a browser-specific driver due to unique ways of setting up sessions in every browser.
The next step is downloading a support driver. We have chosen the Chrome driver
for the current example.
brew install chromedriver Key steps
Now we’re all set for writing the logic for scraping online data with Selenium and Python. Try to complete it in the following manner.
Step 1 - Import the required modules
Start with importing the necessary modules, notably:
- the module for initializing or launching a browser;
from selenium import webdriver- the module for imitating keyboard keys;
from selenium.webdriver.common.keys import Keys- the module for searching elements by specified parameters;
from selenium.webdriver.common.by import By- the module for waiting until a web page loads;
from selenium.webdriver.support.ui import WebDriverWait- the module for waiting until the expected conditions become visible before the remaining code is executed:
from selenium.webdriver.support import expected_conditions as ECStep 2 - Initialize the WebDriver
As it was already mentioned above, Selenium needs the WebDriver API to emulate natural behaviour of a regular user. Don’t forget that with every other browser the WebDriver is implemented differently.
This is how an instance of the Chrome WebDriver (used in our example) should be created to grant you access to all of its useful features:
driver = webdriver.Chrome()If everything is correct, the presented code should launch Chrome in a headful mode, which looks like a regular window. You will see a message on the top of the browser, informing you that the automated script has taken over.
You’ll find directions to launching a headless browser further in this guide.
Step 3 - Choose the web page
What you need to do next is to navigate to the web page of your choice, using the driver.get method.
Here is the relevant example:
driver.get("https://api.rocketscrape.com?apiKey={{YOUR_API_KEY}}&url=https://www.zappos.com/men-boots/CK_XARCz1wHAAQLiAgMBAhg.zso?s=bestForYou/desc")Step 4 - Locate the search results
You may have noticed that, when a web page is loading, not all the elements may visually appear right away. That happens because most websites these days use AJAX techniques for loading their content. Thus, you may face complications while locating elements to scrape, if they are loaded at different intervals.
Nonetheless, one of the best functionalities of Selenium WebDriver is the “wait feature” which deals with this issue for the users. The waiting helps to ensure the essential elements are fully loaded in the DOM before the tool locates them.
See the example below for a demonstration of WebDriver waiting for the element in question to appear on the page prior to executing a subsequent code.
You will need to engage both WebDriverWait method and ExpectedCondition method to make it work.
Selenium needs to be conditioned to wait for 20 seconds for the dv-z class to appear on the webpage. And a TimeoutException will be initiated if the search element is not located within 20 seconds.
Mind you that, upon examining the search results, you will see that all the relevant items are enclosed in a dv-z class.
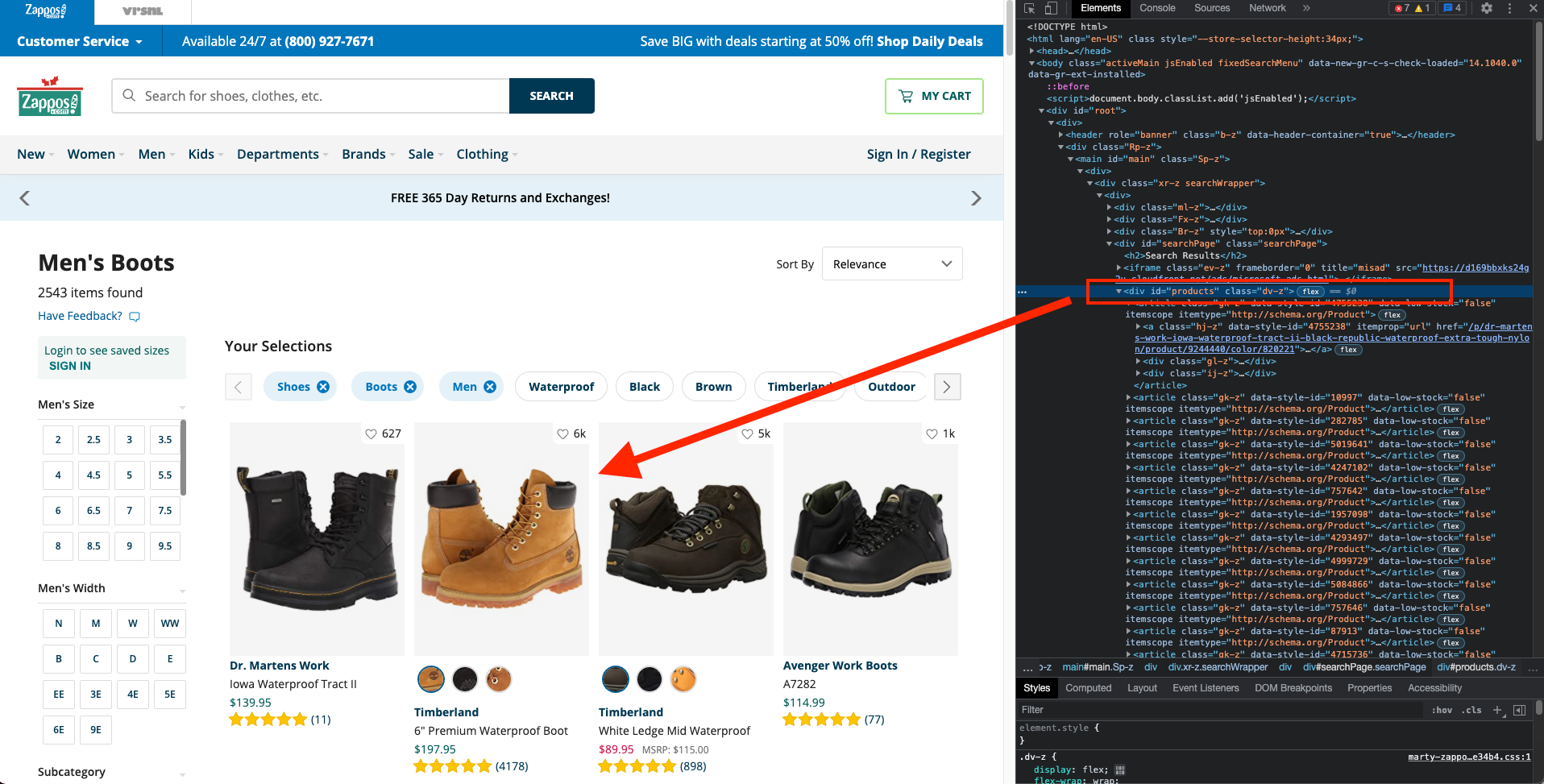
See the example of the code:
search_results = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.CLASS_NAME, "dv-z")))
Step 5 - Scrape the data of a products
Now you can finally scrape the data, obtained with the search results.
You will now see that all headings are located within a <article> tag and the <a> tag.
In order to compose the selected posts into a list use the following code:
products = search_results.find_elements_by_css_selector("article") Afterwards, you can extract content from each of the data:
for product in products:
data = product.find_element_by_tag_name("a")
print(data.text)Step 6 - Quit the browser
You can do so with the following code:
driver.quit()Results
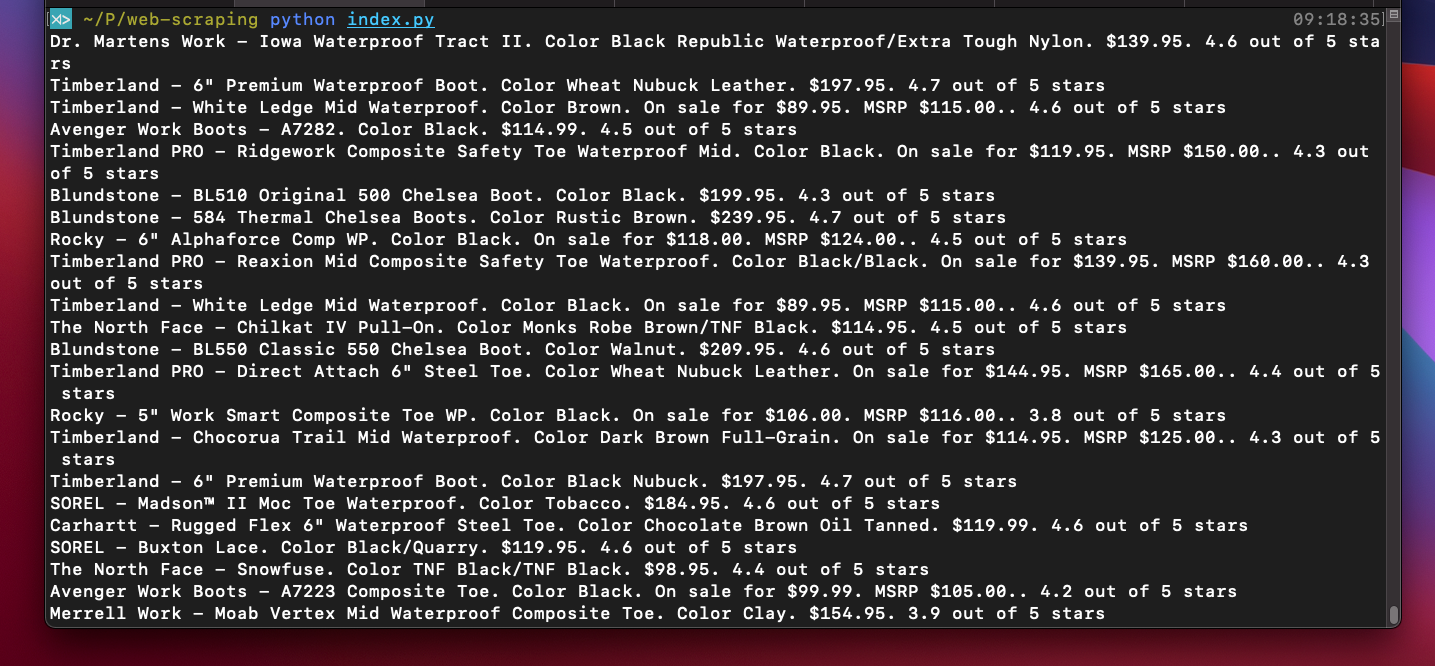
Finally, we present all the code fragments, used for scraping the content on the Zappos webpage with Python and Selenium, composed for your convenience:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# initialize webdriver
driver = webdriver.Chrome()
# navigate to web page
driver.get("https://api.rocketscrape.com?apiKey={{YOUR_API_KEY}}&url=https://www.zappos.com/men-boots/CK_XARCz1wHAAQLiAgMBAhg.zso?s=bestForYou/desc")
assert "No results found." not in driver.page_source
try:
# locate search results
search_results = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.CLASS_NAME, "dv-z")))
# scrape products headings
products = search_results.find_elements_by_css_selector("article")
for product in products:
data = product.find_element_by_tag_name("a")
print(data.text)
finally:
# quit browser
driver.quit()Here are the results we obtained from our instructional scraping, shortened for demonstration purposes:
Optional features for advanced web scraping
With a little bit more skill and effort, you can set up Selenium for more complex web scraping procedures. For instance, it can be conditioned to execute JavaScript, use proxies, as well as a headless browser version.
- JavaScript
Occasionally, the entire web page may not be loaded right away, which means that you will have to scroll down for the remaining HTML to emerge. That is when executing JavaScript on the page in question will come in handy.
Selenium can perform this with an execute_script method, that is designed to add any JavaScript code in its parameter.
This is what it looks like:
scroll_page_down = "window.scrollTo(0, document.body.scrollHeight);"
driver.execute_script(scroll_page_down)IMPORTANT: A usual JavaScript function, used for scrolling the page till particular coordinates, is scrollTo(x_coordinates, y_coordinates). However, in the example, document.body.scrollHeight is applied with a view to uncover the entire height of the body element.
- Proxies
Some websites may try to intervene with your scraping goals, due to their strict policies, and complicate your work. Luckily, there is a "premium" proxies feature available, a possibility to bypass access restrictions. You can read more about advanced functionality of our API here. In particular, you can set a modifiable "country_code" option, which will allow you to choose your preferred region yourself, making your scraper able to collect the much-needed data swiftly and efficiently.
Here is a demonstration of writing proxy settings into Selenium:
from selenium import webdriver
# other imports here
PROXY = "127.63.13.19:3184" #HOST:PORT or IP:PORT
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=%s' % PROXY)
chrome = webdriver.Chrome(options=chrome_options)
chrome.get("https://api.rocketscrape.com?apiKey={{YOUR_API_KEY}}&url=https://www.zappos.com/men-boots/CK_XARCz1wHAAQLiAgMBAhg.zso?s=bestForYou/desc")
# more code hereHeadless browser
A very useful Selenium feature is a headless mode, applied for running a browser without displaying the visual user interface. This option is chosen when a smoother user experience is required, notably in production environments.
Here is the code for a headless mode integration (on the example of Chrome):
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# other imports here
options = Options()
options.headless = True
driver = webdriver.Chrome(CHROMEDRIVER_PATH, chrome_options=options)
driver.get("https://api.rocketscrape.com?apiKey={{YOUR_API_KEY}}&url=https://www.zappos.com/men-boots/CK_XARCz1wHAAQLiAgMBAhg.zso?s=bestForYou/desc")
# more code hereConcluding statements
In this article, we have demonstrated how web scraping procedures involving Selenium can be integrated with Python coding language, especially during data extraction attempts from dynamic websites and web pages, loaded with JavaScript.
Obviously, this is only a small fragment of all the possible advantages of Selenium and Python combination for web scraping purposes. Should you wish to study the notion more thoroughly, feel free to examine closely the Selenium with Python documentation here.
All the aspects of this tutorial are provided for easily accessible introduction exclusively.
Good luck with your scraping beginnings!