
Nowadays online data is, basically, located in the public domain, potentially accessible to everyone. Despite this fact, regular users sometimes face difficulties, while attempting to obtain it. The main cause of the matter usually lies in the data’s original owners, who might choose to restrict access to information by refusing to provide a formal web API or to present their data in a downloadable format. When data is stored in an unstructured format, efforts and time devoted to its manual extraction become unjustified. That’s why web scraping procedures were invented in order to overcome these restrictions. This method is rather fast, efficient and convenient, as opposed to manual work. Very important types of research, such as market study, competitive analysis, price monitoring, would be seriously impeded without information gathering. The following article contains basic knowledge on PHP-based scrapers that will be useful for collecting important data from the website.
Brief summary of the article:
- PHP practical application in web scraping
- Overview of PHP-based web scraping libraries and tools
- Principles of building a web scraper with PHP
- How to build a web scraper using Goutte and Guzzle
- Conclusions
PHP practical application in web scraping
PHP is a coding language, most commonly used in server-side programming. PHP-based scraping is rather user-friendly in 2022, due to the process becoming much more widespread over the years, simplified by numerous extra libraries and tools. We are going to introduce some of those PHP libraries and tools to you. In such a way, there will be no need to dedicate time and effort to learning a new programming language, if you’re already somewhat familiar with PHP.
Resorting to PHP-based software and tools is especially useful when the application, that the data has been extracted for, has also been written in PHP. Users might face obstacles should they attempt to use a PHP web scraper alongside a web application written in Python, or any other programming language. Thus, PHP usage is indeed much more advantageous in certain situations.
Besides, it is important to keep in mind that PHP is capable of automating the whole web scraping process using CRON-jobs. To elaborate, a CRON-job is a software utility, used to schedule the tasks.
Overview of PHP-based web scraping libraries and tools
As it is mentioned above, a number of tools and libraries are available for PHP in 2022. Generally speaking, these libraries can be split into two categories, which are:
- PHP web scraping libraries
- PHP web request libraries
They are both able to make requests with all the common HTTP methods and retrieve the HTML body from a web page. What differs one from the other is that a web request library is unable to help with parsing the web page, obtained by your HTTP request. Moreover, with PHP web request libraries it is impossible to make a series of requests in a row while moving around web pages you are attempting to scrape.
Both these types of libraries are reviewed in detail below.
Simple HTML DOM parser
With HTML Dom parser you can manipulate HTML by using selectors to find HTML elements. All you need to scrape a web page for data is a single line with HTML DOM parser. Though it should be noted that it operates slower than certain other libraries.
cURL
“Client for URLs”, often referred to as cURL, is an integrated PHP element, widely used as a PHP web request library at the same time. It is known for its web scraping method by means of strings and regular expressions.
Goutte
Goutte is a PHP library, built with the Symfony framework. It offers APIs that scrape the websites for their content involving HTML/XML responses.
Guzzle
Guzzle is also a widely known PHP web request library used for sending HTTP requests that features an intuitive API, capable of extensive error handling. It can also be potentially integrated with middleware.
Principles of building a web scraper with PHP
Simple HTML DOM parser
This passage is, essentially, a guide to building a web scraper with a simple HTML DOM parser.
Help yourself to this link in order to download the latest version of the simple HTML DOM parser. Unzip the file once the download is complete.
Next step is to create a new directory and place the simple_html_dom.php file within. Then, create a new file, naming it scraper.php and save it to the same newly-created directory.
Use a text editor of your choice to open the scraper.php file and add a reference to the simple HTML DOM parser library at the very beginning of your script. This is how you gain access to all the library’s features and components. Here is what it should look like:
<?php
require_once ‘simple_html_dom.php’;
?>For demonstration purposes, we are about to scrape user reviews for “The Gentlemen” movie from IMDB.com. The web page used in our example is https://www.imdb.com/title/tt8367814/reviews.
First of all, let’s create a DOM object, where we will store the extracted data. What you have to do is create a variable called $html and assign a DOM object to it, which you can get from file_get_html_() function. It can be done as follows:
$curl = curl_init();
curl_setopt_array($curl, array(
CURLOPT_URL => 'https://api.rocketscrape.com?apiKey={{YOUR_API_KEY}}&url=https://www.imdb.com/title/tt8367814/reviews',
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => '',
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 0,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => 'GET',
));
$response = curl_exec($curl)
$html = str_get_html($response);IMPORTANT: We will explain how to optimize data fetching in later paragraphs.
In this example the gathered data will include the number of star ratings, the headings of the review, and the reviews content itself.
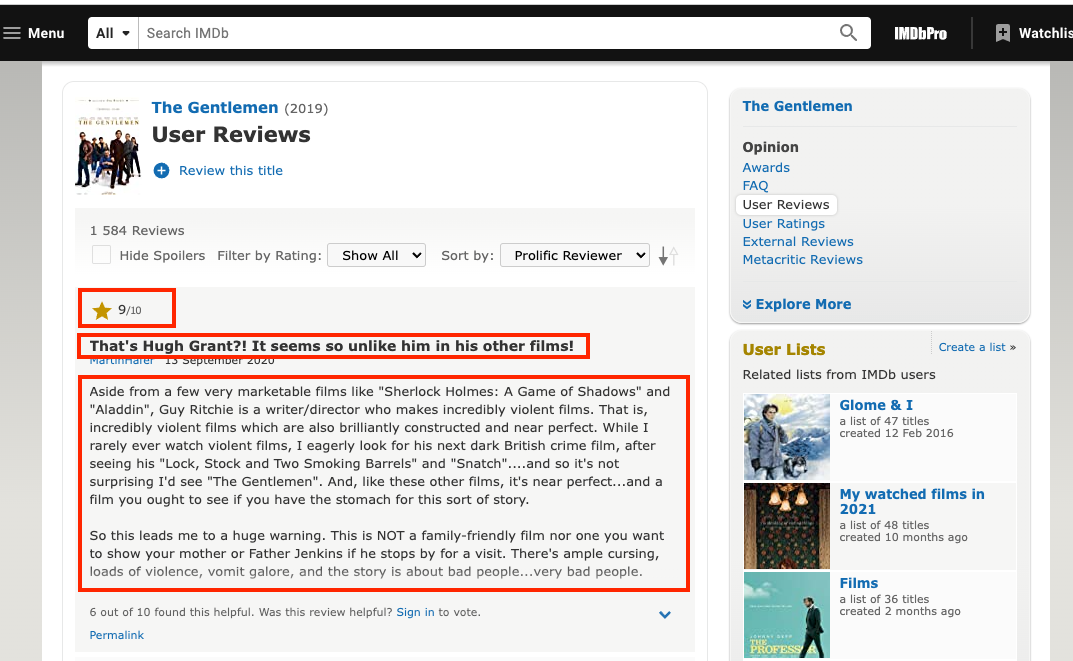
Next, you will need to study the web page in your browser in order to identify HTML elements and CSS selectors you need to scrape.
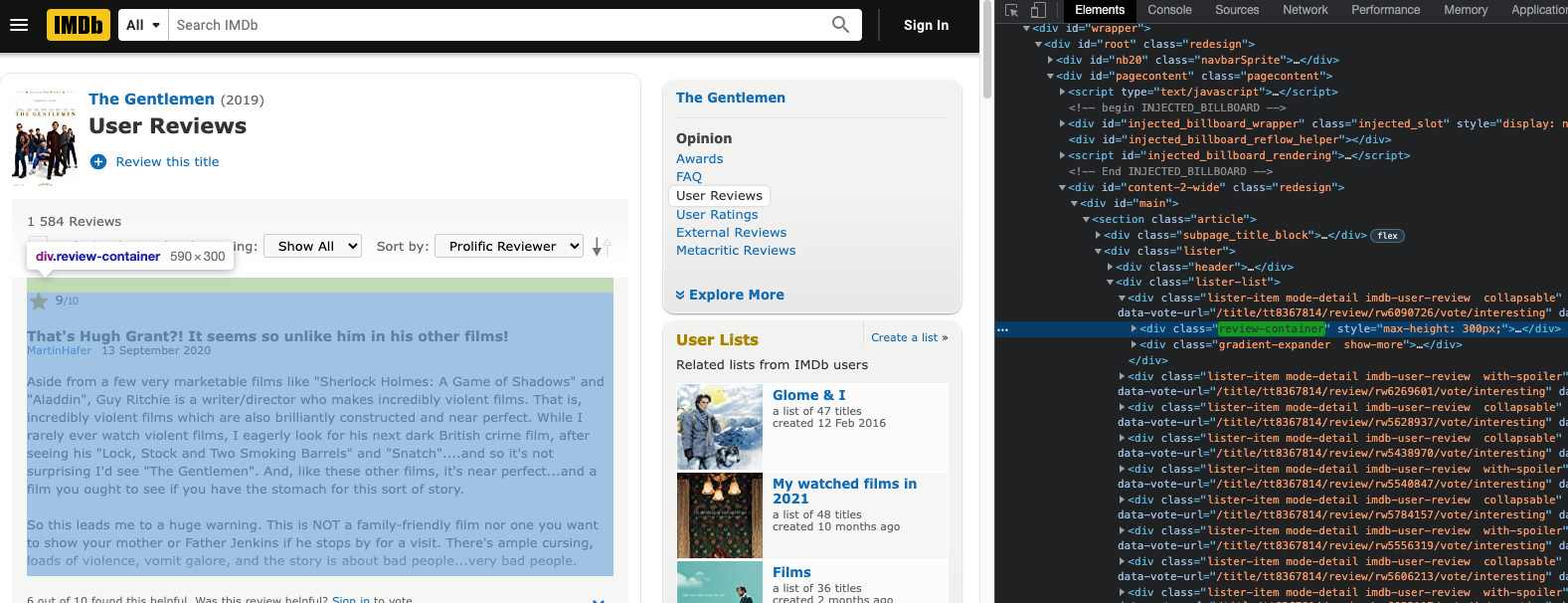
In this case, you can notice right away an HTML div element and a CSS class selector (review-container), that store the required data.
Once you have identified that, use a foreach loop to extract the content from all the user reviews with the help of that class selector. Within the review-container, class selectors refer to the corresponding data as follows:
- Ipl-ratings-bar = the number of star ratings
- title = the heading of the review
- Text show-more__control = the content of the review
Similarly, a foreach loop can be used for those three CSS selectors. See the demonstration below for properly integrating this code into your script.
Complete Code Snippet
<?php
include('./simple_html_dom.php' );
$curl = curl_init();
curl_setopt_array($curl, array(
CURLOPT_URL => 'https://api.rocketscrape.com?apiKey={{YOUR_API_KEY}}&url=https://www.imdb.com/title/tt8367814/reviews',
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => '',
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 0,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => 'GET',
));
$response = curl_exec($curl);
$results = array();
$html = str_get_html($response);
if (!empty($html)) {
$div_class;
$i = 0;
foreach ($html->find(".review-container") as $div_class) {
//Extract the review title
foreach ($div_class->find(".title") as $title) {
$results[$i]['title'] = $title->plaintext;
}
//Extract the number of star ratings
foreach ($div_class->find(".ipl-ratings-bar") as $ratings) {
$results[$i]['ratings'] = $ratings->plaintext;
}
//Extract the review content
foreach ($div_class->find('div[class=text show-more__control]') as $description) {
$content = html_entity_decode($description->plaintext);
$content = preg_replace('/\'/', "", $content);
$results[$i]['description'] = html_entity_decode($content);
}
$i++;
}
}
print_r($results);You should now have all your extracted data gathered in an array named $results. If you try to print said array, it will look something like this:
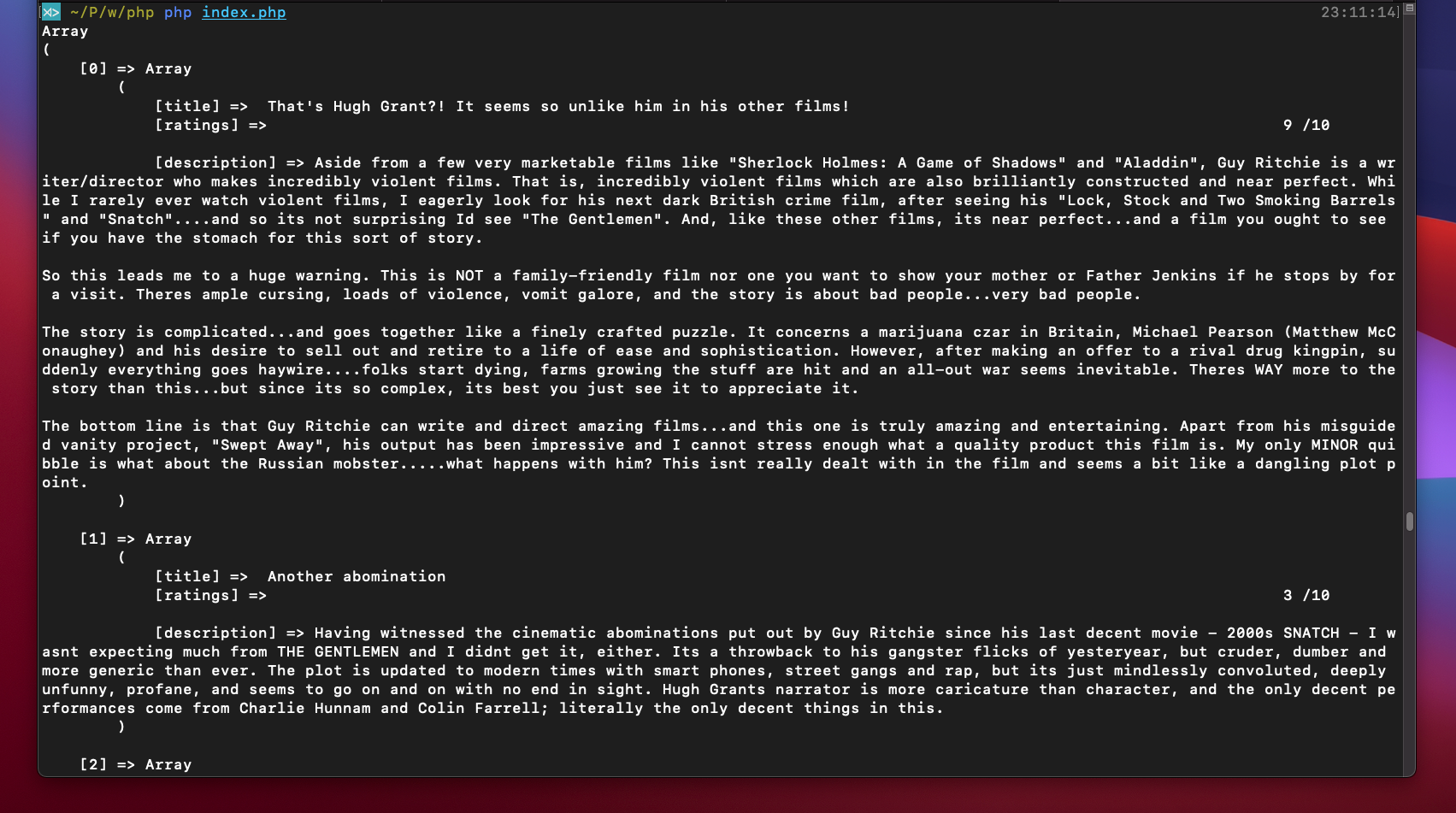
The scraping output can afterwards be stored in an XML file. To make it happen you have to use SimpleXMLElement, which is a built-in class. It will help you to reorganize the obtained $results array into an XML component. The code must be written in the following manner:
function convertToXML($results, &$xml_user_info){
foreach($results as $key => $value){
if(is_array($results)){
$subnode = $xml_user_info->addChild($key);
foreach ($value as $k=>$v) {
$xml_user_info->addChild("$k", $v);
}
}else{
$xml_user_info->addChild("$key",htmlspecialchars("$value"));
}
}
return $xml_user_info->asXML();
}
$xml_user_info = new SimpleXMLElement('<?xml version=\”1.0\”?><root></root>');
$xml_content = convertToXML($results,$xml_user_info);At last, you receive an XML file with all the extracted data. That’s how it is done using the simple HTML DOM parser.
How to build a web scraper using Goutte and Guzzle
Now you are going to learn about building a web scraper with the help of Guzzle and Goutte libraries, as was stated to be an option earlier in the article. Take into account that you must work with PHP 5.5 or a higher version and have Guzzle 6 or its newer release installed to use Goutte. Basically, Goutte is a thin wrapper around the following Symfony Components: DomCrawler, BrowserKit, CssSelector and the Guzzle HTTP client component. A package manager for PHP called Composer is a requirement for Goutte installation.
Installing Composer
You can find the download link here.
You must install Goutte using Composer, when it is successfully installed. This is the command you have to use to install Guzzle prior to installing Goutte, since the latter depends on it.
composer require guzzlehttp/guzzleNext, execute the following command to install Goutte.
composer require fabpot/goutteAlso, you will need another library, called Masterminds, which should be installed with the following command.
composer require masterminds/html5Once these steps are complete, the dependencies in the composer.json file will be automatically updated. The relevant code snippet looks like this.
{
"require": {
"guzzlehttp/guzzle": "^7.2",
"fabpot/goutte": "^4.0",
"masterminds/html5": "^2.7"
}
}Building the Scraper
Finally, we have all the components at our disposal. To proceed with the scraper, create a new file and name it Goutte_scraper.php. You should now enable autoload so it loads all the files required for your project. Add this code to the beginning of your script to enable autoload.
require 'vendor/autoload.php';After that, create a Goutte client instance, named $client , using the following code:
$client = new \Goutte\Client();See the snippet of code below for an example of making the HTTP requests with request() method. The request() function returns a crawler instance. The provided example is using the same website as the preceding scraping demonstration with a simple HTML DOM parser. The difference is that our current target for this illustration is the headings of the reviews.
The scraped web page URL: https://www.imdb.com/title/tt8367814/reviews The CSS class selector of the review headings that we are about to extract is ‘title’.
Use an HTTP GET request to get the webpage by inserting the following code into the script:
$crawler = $client->request('GET', 'https://api.rocketscrape.com?apiKey={{YOUR_API_KEY}}&url=https://www.imdb.com/title/tt8367814/reviews');The following fragment of code will extract the review headings for you:
$results = [];
$results = $crawler->filter('.title')->each(function ($node) use ($results) {
array_push($results, $node->text());
return $results;
});The whole code snippet should be similar to this:
<?php
require 'vendor/autoload.php';
$client = new \Goutte\Client();
$crawler = $client->request('GET', 'https://api.rocketscrape.com?apiKey={{YOUR_API_KEY}}&url=https://www.imdb.com/title/tt8367814/reviews');
$results = [];
$results = $crawler->filter('.title')->each(function ($node) use ($results) {
array_push($results, $node->text());
return $results;
});The resulting compilation in our example appears as follows:
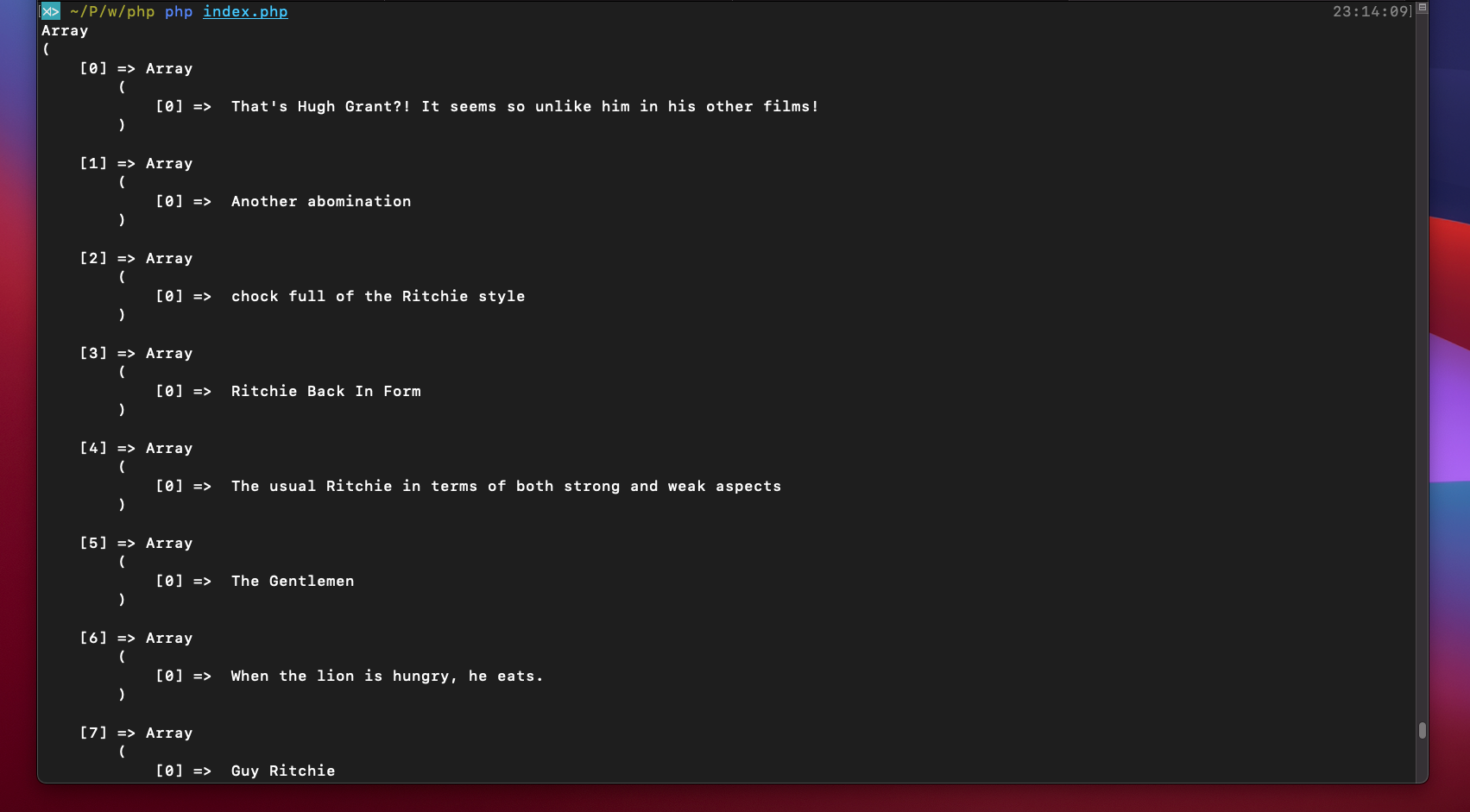
In such a manner, we have completed the entire exercise by successfully setting up a working web scraping tool using Goutte and Guzzle libraries.
Conclusions
The importance of web scraping in backend development cannot be overstated. Being among leading backend development languages, PHP has a huge support for libraries and tools, designed for data collection. It is unnecessary to define which tools and libraries are preferable, since each can be applied for different circumstances, and has its own pros and cons. Simply pay close attention to selecting a suitable tool and make sure it meets your requirements. You may find other helpful tutorials in our blog. Good luck with your scraping beginnings!